Musical Genre Prediction
In this project, I analyzed a dataset to predict the musical genre of popular songs based on the songs characteristics. The characteristics are the followings: artist, track, duration, popularity, dance-ability, energy, key, loudness, mode, speediness, acoustics, instrumentals, liveness, valence, tempo, time signature. The dataset given was cleaned and filtered for the purpose of focusing building the machine learning models, so the dataset only contains the above features and the targeted feature genre to test the accuracy of the model. However, the given dataset still need to go through the process of encoding, normalization, and splitting the data set in order to build the machine learning model.

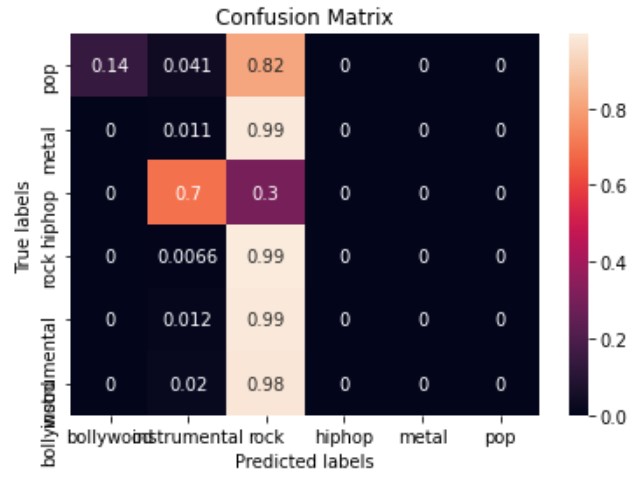
The chosen model for predicting the genre was linear support-vector machines(SVM) classifier, because the problem that we dealt with was a classifying problem. After training the model, I compute accuracy of the model and both for the train and test accuracy are not great which is around 50%. Thus, I optimized the hyper parameters C, gamma, and the kernel, using a randomized search approach with 3-fold cross-validation to increase the performed of the model. At the end, I compute the confusion matrix for the best model and displayed in heat map format.
For this project, I learned how does a supervised linear model can work with classifying type of problem to make accurate predictions. In addition, I learned about how to further process data such as splitting, encoding and normalization, to make the dataset fit into the model, especially using what type of process methods are essential. For example, in this case, encode the data with its original order through normalization is the the right choice and other types of encoding such as ordinal encoding and one hot encoding are bad idea. Because for ordinal encoding, it implicitly indicate the order of artist or track name which may affect the model. For one hot encoding, since the names are all different and the list is huge, there will be high memory consumption due to the rapidly increasing of the dimension of the matrix and the encoded data is not useful for the model as well.
You can learn more at source codes: predicting musical genre.